Wednesday, 15 July 2026


Image source: Public Domain
Dahua Technology, a leading global provider of video-centric AI solutions and services, officially launched its Xinghan Large-Scale AI Models, a next-generation, industrial-grade AI system that integrated large-scale visual intelligence with multi-modal and linguistic capabilities. Designed to tackle the complex challenges of real-world environments, Xinghan marked a significant leap in Dahua's ongoing innovation efforts, driving intelligent transformation across multiple industries.
Xinghan Technological Foundation
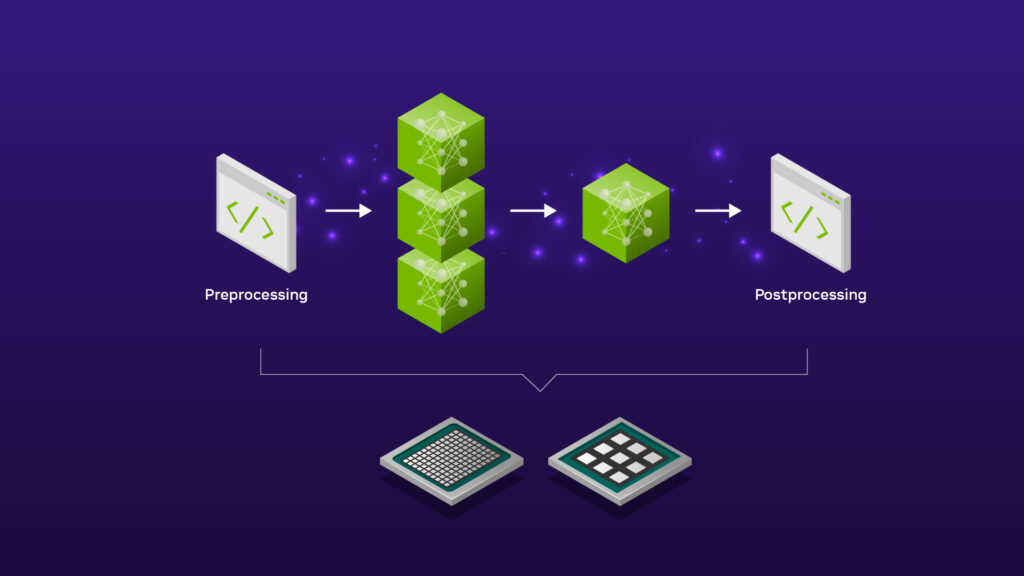
With the mission of enabling machines to truly understand the world, the Xinghan model system continues to evolve, connecting cutting-edge research with real-world applications. Named after the Chinese word for "galaxy," Xinghan offers a comprehensive capability matrix driven by the synergy between the edge and the cloud, enabling scalable and adaptive intelligence across all industries. Xinghan's enhanced architecture consists of three core model series: L, V, and M. The L series model focuses on natural language understanding and interaction, while the other two address more specific applications:
Series V: Xinghan Vision Models
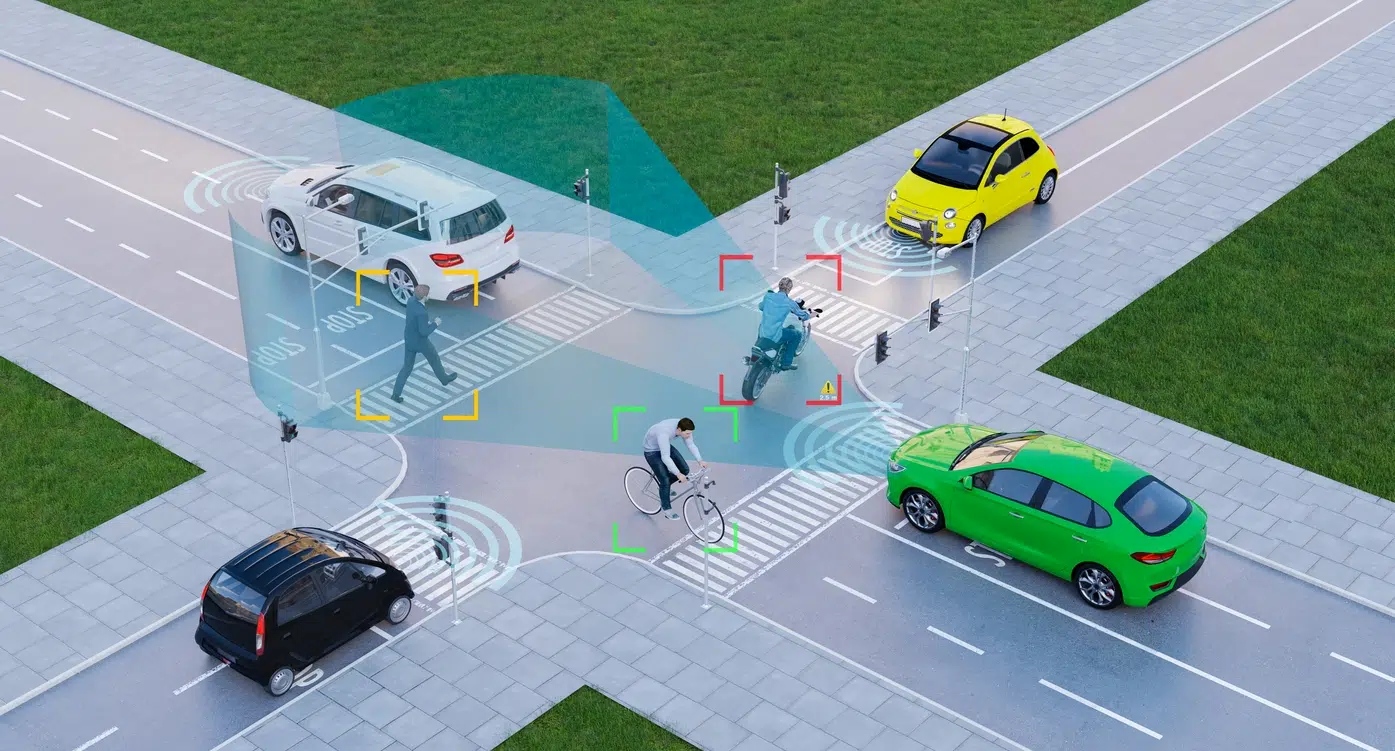
Centered on advanced visual intelligence and video analytics, this series optimizes target categories by focusing on key targets (e.g., humans, motorized and non-motorized vehicles) to reduce model complexity while maintaining high accuracy.
Main features:
M Series: Xinghan Multimodal Models
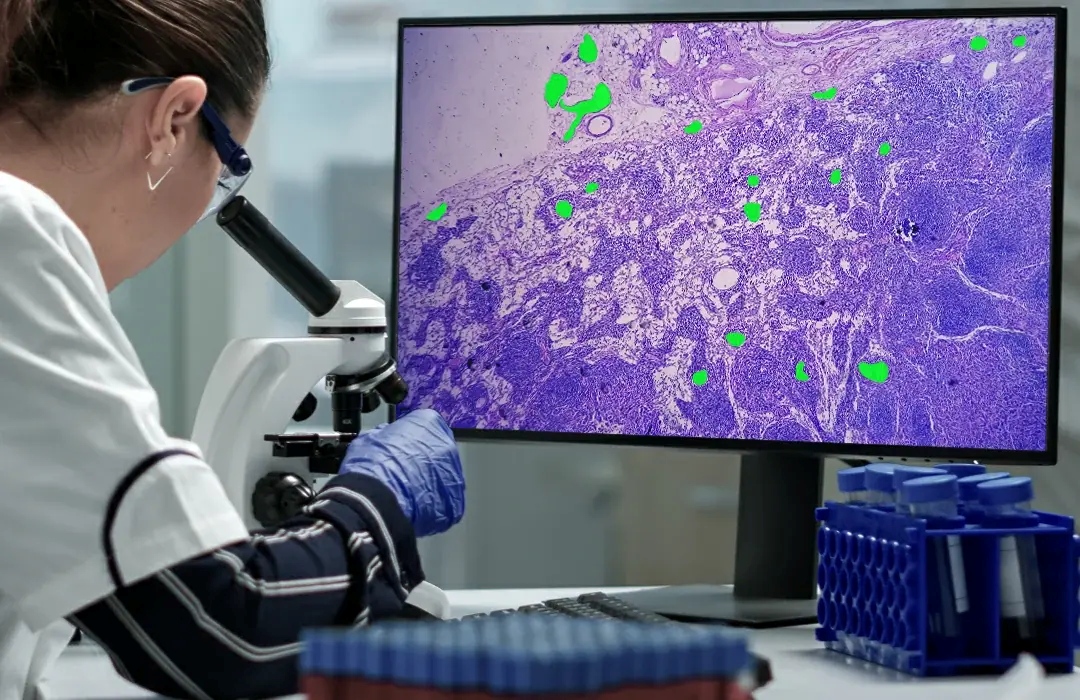
Multimodal models are advanced AI systems capable of simultaneously processing and thoroughly integrating multiple types of heterogeneous data (e.g., text, images, audio, and video). This significantly improves information processing efficiency, enables more natural human-computer interaction, and opens up a wider range of application scenarios.
Main features:









By subscribing, you agree to receive email related to content and products. You unsubscribe at any time.
Copyright 2026, AI Reporter America All rights reserved.